

Is AI sufficiently safe to deploy in a cancer care setting?
Is AI sufficiently safe to deploy in a cancer care setting?
Sai Anurag Modalavalasa
Sai Anurag Modalavalasa
Observations from a scientific study in TMH
After multiple working sessions with clinicians at Tata Memorial Hospital, Anukriti and I could see that AI systems can address real pain points in clinical operations (e.g., writing discharge summaries, consult notes, and tumour board notes) and research operations (e.g., creating disease registry entries and filling clinical trial forms). But before deploying such systems in safety-critical settings, we had to confront one question: Is the AI system sufficiently safe to use in an Indian cancer care environment?
The problem
Public cancer care systems in India face unique large scale, low-resource challenges:
High patient volume per provider: Indian system has 12 physicians per 100,000 population [1] while the US has 247.5 physicians per 100,000 patients[2]). Clinicians often have very limited time per patient.
Information diversity: Clinical documentation may include multiple languages, local drug names, and regional dialects. The inputs are highly variable, while the outputs must conform to standardized clinical templates for the system to be usable
Infrastructure constraints: Point-of-care environments often have high ambient noise, shared workspaces, and intermittent internet connectivity.
To evaluate whether the AI system can reliably execute tasks under these hard conditions, we conducted a prospective study at TMH involving 300 patient encounters. We compared the baseline workflow (physicians leave shorthand notes, which staff then process into the EHR) with the AI-assisted workflow (physicians use an ambient AI system directly). We tracked three key physician-rated accuracy metrics:
Meaningfulness score: A qualitative 10-point metric, independently rated by clinicians
Hallucinations: Instances where the AI generated unsupported, incorrect information
Minor errors in details: For example, incorrect drug names or interpretation mistakes
Findings from the field

A 9.1/10 meaningfulness score indicates that physicians find the AI-generated output to be of high quality and trustworthy. With 0 hallucinations observed across 300 independent encounters, we can conclude with 95% confidence that the system demonstrates ≥99% reliability. Additionally, the AI reduced the rate of minor errors in details from 55% in the baseline workflow to 30%.
Taken together, these results indicate that AI systems with operational controls can be safely deployed in Indian cancer care settings. Our observations suggest that instant output generation, a user-friendly review interface, adaptive learning capabilities, and high baseline reliability help in earning clinicians’ trust.
Update (Poster presented at ESMO)
Taking an open, scientific, evidence-based approach and exposing our methods, assumptions, and results to the ecosystem enhances our research culture and accelerates progress. In this spirit, we submitted the findings from our prospective study at Tata Memorial Hospital as a scientific abstract for peer-review. Our work was accepted [3] and presented at the European Society for Medical Oncology (ESMO) AI & Digital Oncology Congress 2025 in Berlin (poster attached below).
By transparently sharing this work, we aim to contribute to standardized evaluation approaches and benchmarks. We hope this facilitates further collaboration between clinicians, healthcare systems, and the builder community. We thank the researchers from Tata Memorial Hospital for partnering with us in defining metrics, collecting and analyzing data, and publishing the research, and we welcome critique and collaboration from the broader community.
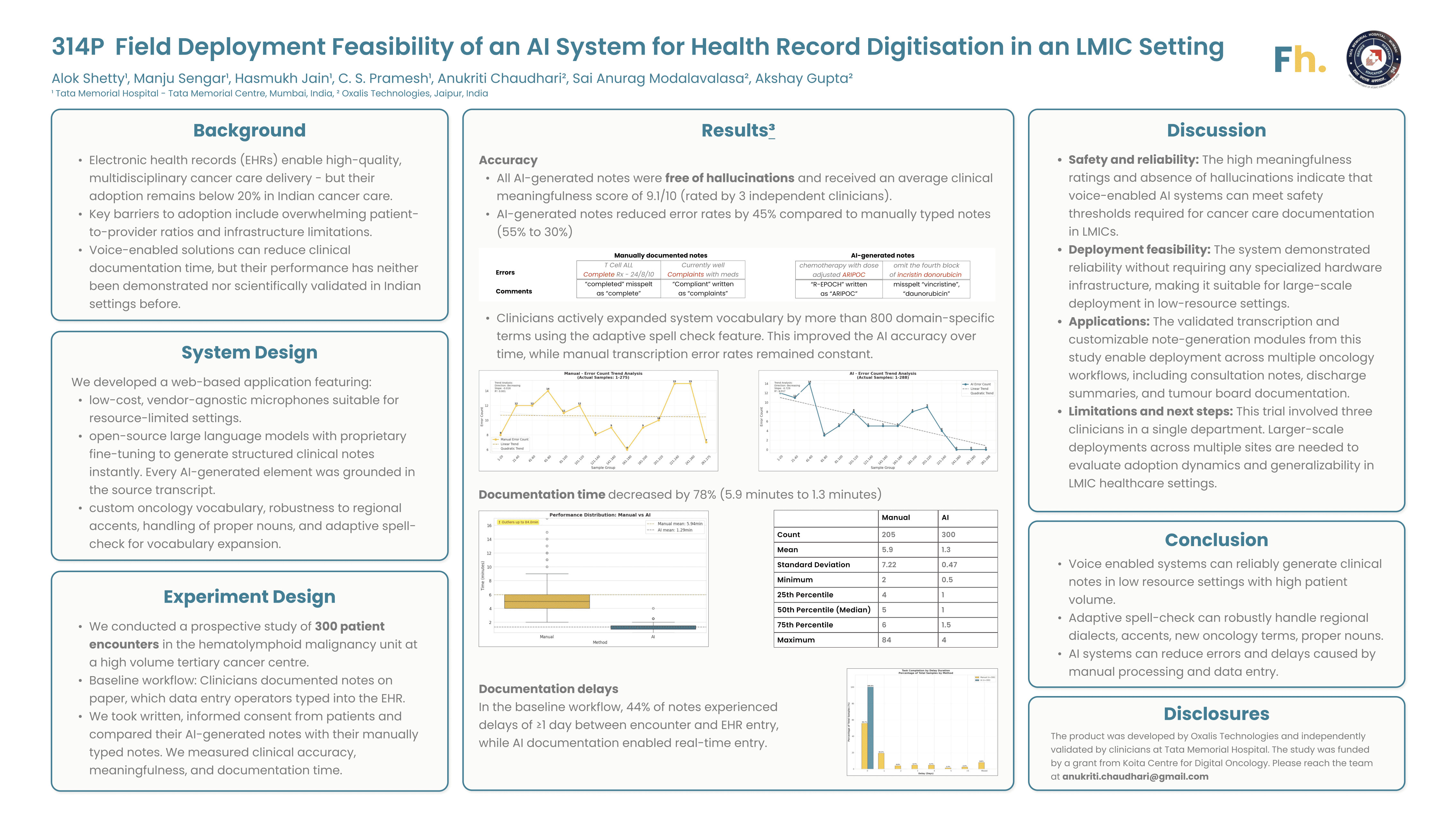
Reused with permission from the European Society for Medical Oncology (ESMO). This abstract was accepted and previously presented by Manju Sengar et al. at the ESMO AI & Digital Oncology Congress 2025, FPN: 314P, ESMO Real World Data and Digital Oncology, Volume 10, 2025 Supplement. All rights reserved.
Observations from a scientific study in TMH
After multiple working sessions with clinicians at Tata Memorial Hospital, Anukriti and I could see that AI systems can address real pain points in clinical operations (e.g., writing discharge summaries, consult notes, and tumour board notes) and research operations (e.g., creating disease registry entries and filling clinical trial forms). But before deploying such systems in safety-critical settings, we had to confront one question: Is the AI system sufficiently safe to use in an Indian cancer care environment?
The problem
Public cancer care systems in India face unique large scale, low-resource challenges:
High patient volume per provider: Indian system has 12 physicians per 100,000 population [1] while the US has 247.5 physicians per 100,000 patients[2]). Clinicians often have very limited time per patient.
Information diversity: Clinical documentation may include multiple languages, local drug names, and regional dialects. The inputs are highly variable, while the outputs must conform to standardized clinical templates for the system to be usable
Infrastructure constraints: Point-of-care environments often have high ambient noise, shared workspaces, and intermittent internet connectivity.
To evaluate whether the AI system can reliably execute tasks under these hard conditions, we conducted a prospective study at TMH involving 300 patient encounters. We compared the baseline workflow (physicians leave shorthand notes, which staff then process into the EHR) with the AI-assisted workflow (physicians use an ambient AI system directly). We tracked three key physician-rated accuracy metrics:
Meaningfulness score: A qualitative 10-point metric, independently rated by clinicians
Hallucinations: Instances where the AI generated unsupported, incorrect information
Minor errors in details: For example, incorrect drug names or interpretation mistakes
Findings from the field
A 9.1/10 meaningfulness score indicates that physicians find the AI-generated output to be of high quality and trustworthy. With 0 hallucinations observed across 300 independent encounters, we can conclude with 95% confidence that the system demonstrates ≥99% reliability. Additionally, the AI reduced the rate of minor errors in details from 55% in the baseline workflow to 30%.
Taken together, these results indicate that AI systems with operational controls can be safely deployed in Indian cancer care settings. Our observations suggest that instant output generation, a user-friendly review interface, adaptive learning capabilities, and high baseline reliability help in earning clinicians’ trust.
Update (Poster presented at ESMO)
Taking an open, scientific, evidence-based approach and exposing our methods, assumptions, and results to the ecosystem enhances our research culture and accelerates progress. In this spirit, we submitted the findings from our prospective study at Tata Memorial Hospital as a scientific abstract for peer-review. Our work was accepted [3] and presented at the European Society for Medical Oncology (ESMO) AI & Digital Oncology Congress 2025 in Berlin (poster attached below).
By transparently sharing this work, we aim to contribute to standardized evaluation approaches and benchmarks. We hope this facilitates further collaboration between clinicians, healthcare systems, and the builder community. We thank the researchers from Tata Memorial Hospital for partnering with us in defining metrics, collecting and analyzing data, and publishing the research, and we welcome critique and collaboration from the broader community.
Reused with permission from the European Society for Medical Oncology (ESMO). This abstract was accepted and previously presented by Manju Sengar et al. at the ESMO AI & Digital Oncology Congress 2025, FPN: 314P, ESMO Real World Data and Digital Oncology, Volume 10, 2025 Supplement. All rights reserved.
